BESSIG Speaker Notes, February 22, 2016
Download the presentation
Extended speaker notes for the BESSIG Software Evaluation presentation, February 22, 2016. There was a lot of discussion so in some cases, this is what I planned on saying but was happy to answer questions as they arose. References can be found on the home page unser Refernces.

What it says on the tin, which is a quick evaluation of software evaluation.

Why are we talking about software evaluation?

We’re talking software evaluation, and technology evaluation more broadly, because ESIP, through its Products & Services committee, provides an testbed (aka incubator). Last fall, one of the testbed projects was to develop a software evaluation metric (based on NASA TRLs and the Software Sustainability Institute’s criteria) for a pilot NASA AIST evaluation effort.
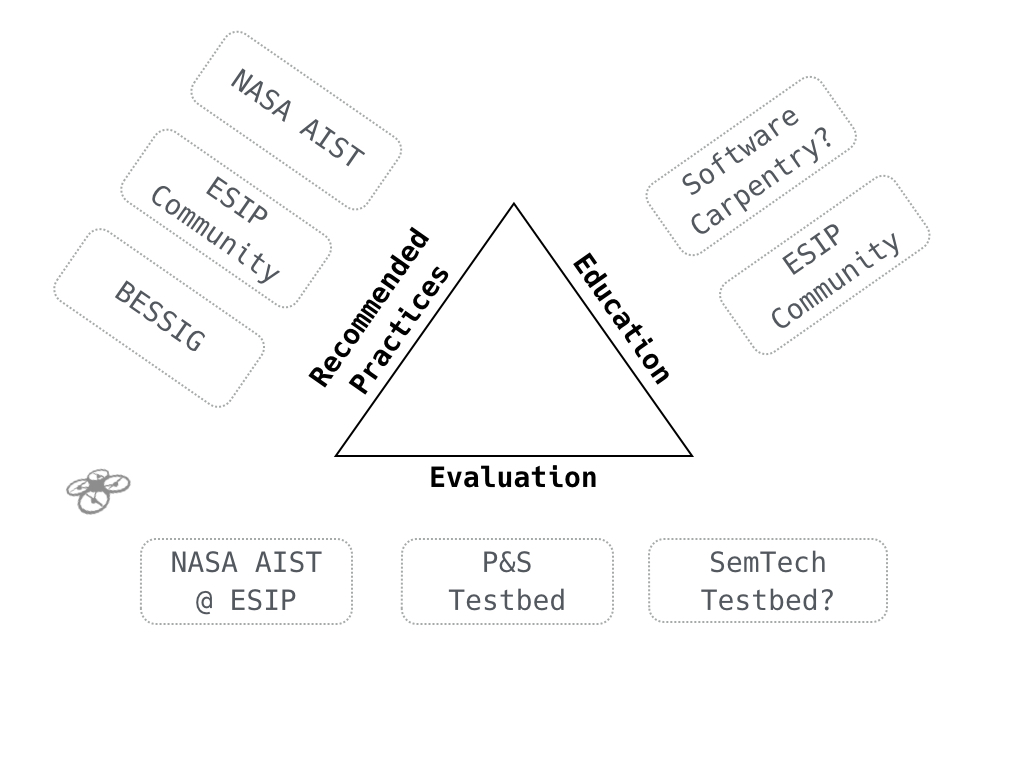
We’d like to expand the evaluation effort beyond the current AIST effort to provide software evaluation (beyond the NASA-centric methods) and to include other types of research objects (datasets, ontologies, or other objects identified by the community).
The ESIP model to support this is threefold: solicit recommended practices or guidelines from the community (as domain experts), develop and maintain an evaluation platform, and to integrate both of those aspects into different educational outlets.
And, just to involve the whole community, we’ll need a way to incorporate drones.
[Please see the Use Cases.]
Currently, the AIST evaluation is from the funder’s side - does the provided TRL match the TRL of the product delivered? It isn’t entirely geared towards the other stakeholders (managers, PIs, science software staff, developers).
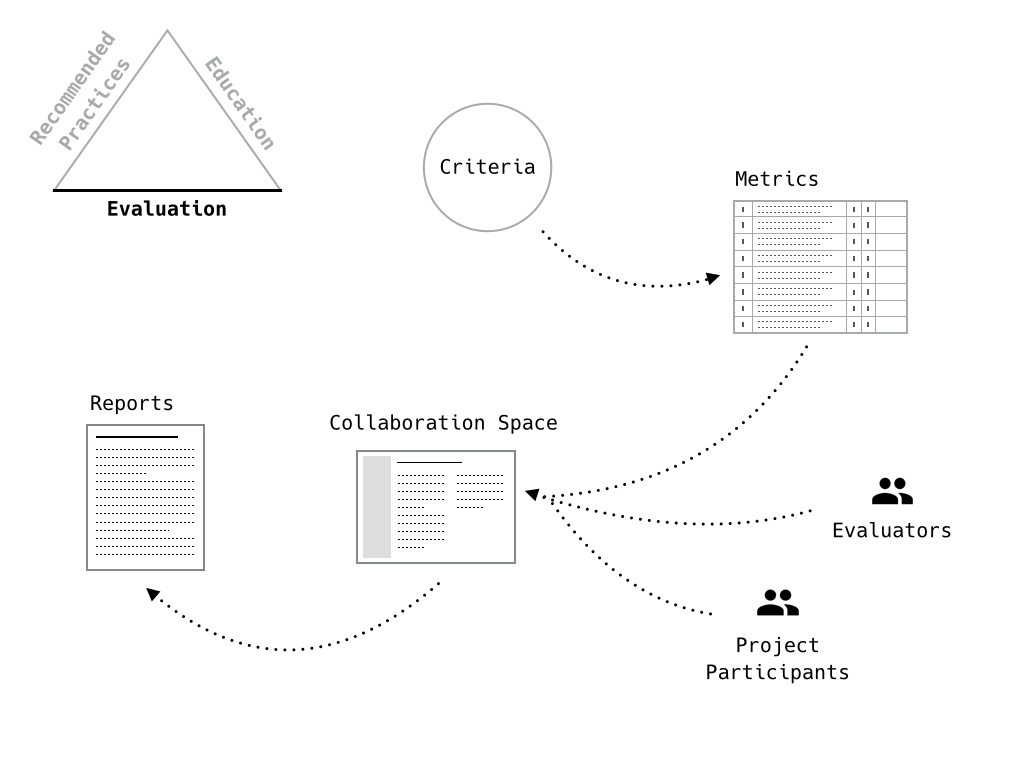
The current evaluation framework.
From some set of criteria, we develop a metric. If we look at just the current AIST metric, a set of criteria was identified and placed within the TRL structure. Each criteria is weighted based on the selected TRL; the metric generates a score between 0-100 to indicate whether the project is at the expected TRL.
The metric is provided to a set of evaluators and, they, along with the project owners/maintainers, work to develop a test plan using a variety of collaboration tools. The evaluators complete the test plan and complete the metric.
Finally, a report is delivered to the project owners and AIST. Note that it’s not solely based on this metric but includes feedback on certain other AIST proposal details.

We’re also adding a new component to the evaluation framework and that is to provide feedback. So a question for further iterations of the framework is how to use the assessments to guide further training or other related activities?
Can we build the tools to support the culture we want to promote? And that culture is one that involves mentorship and education. Capacity building in the ESIP community and in the larger Earth Science community.

[We had not noodled around.]

I have a bad habit and jump to implementation. Sorry about that. But in this case, we have been discussing the larger ESIP goals for tech evaluations so I’ll tip the scales towards those goals rather than simply revising the criteria as they currently exist.

We’ll spend the rest of the time focusing on the recommended practices vertex.
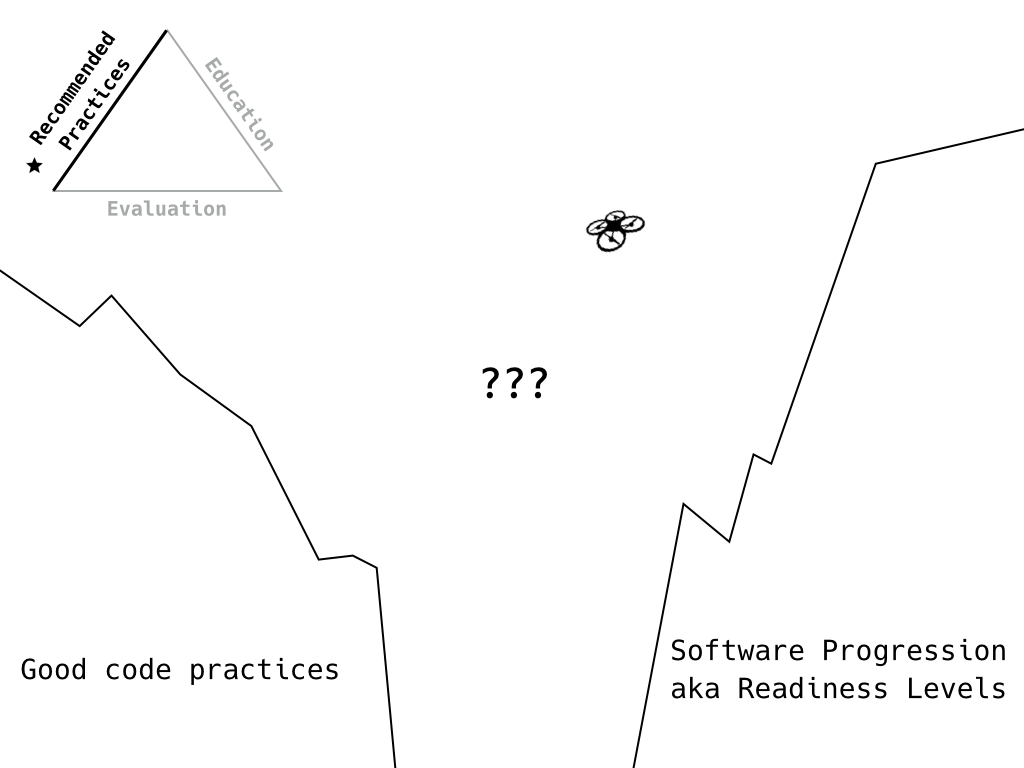
At this point, I’ll admit, I am not sure where we draw the line between good code practices and the concept of Readiness Levels. I am also coming at this as a working dev and as one of the early evaluators rather than any academic perspective.
This is partly due to the different sources of the metric and the biases in those. TRL often tracks as a hardware engineering model applied to software; the SSI criteria were developed for a different purpose (sustainability rather than active development or reuse).
This also might be a good place for drones? We’ll figure it out.

I’ll also note here that the general consensus of the pilot AIST round was that the generated score matched what the TRL that the evaluators felt was appropriate for the project. So the metric, as it stands, tracked from the evaluators’ side.

But the feedback on the metric also indicated a fair amount of uncertainty from the evaluators related to specific criteria and whether they were relevant to the type of project being evaluated.

Again, we are changing the use case from that original AIST requirement. So while the metric is functioning, it isn’t really getting at what we want for the larger ESIP evaluation framework, ie education.
So hang on to this thought.
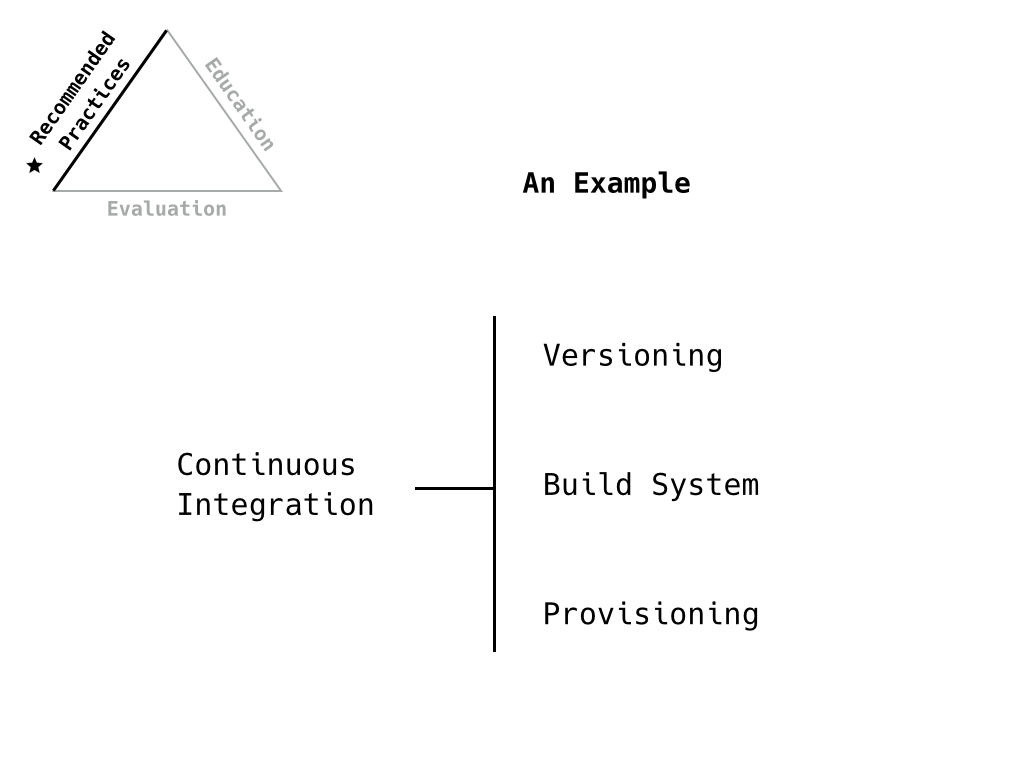
Part of getting at the education question is a a reframing and ordering exercise. Do the criteria provide an understandable and meaningful progression?
Looking at continuous integration, we can say that the criteria we’re looking for is something like “Uses CI tools”. But that’s packed with a lot of other concepts like versioning, build systems, provisioning, testing. We’d like to capture these lower level concepts in the progressions for readiness and for education. This is how we build the scaffold.
It is also about ensuring that we include relevant categories. So what’s missing from the current set? (Security, possibly administration, ??)
In many cases, this is about reframing the existing criteria to meet both goals rather than any major overhaul.
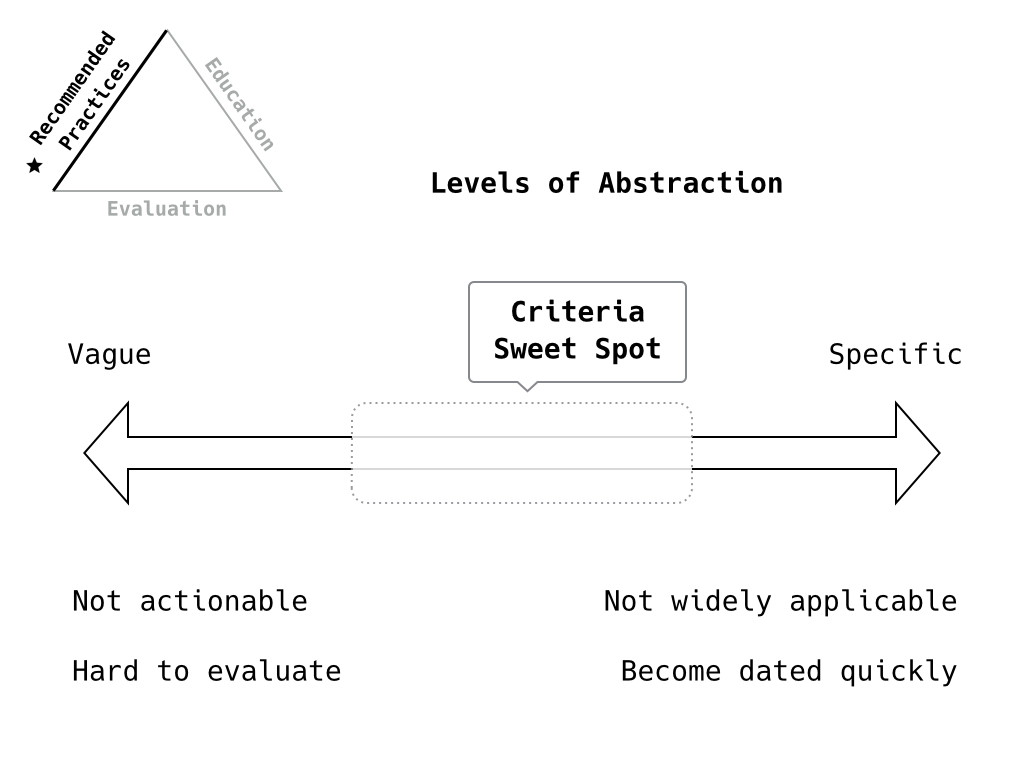
In other cases, we find a mixed bag of abstraction levels. Things that are quite vague and are difficult for an evaluator to assess. Or things that are too specific, like something of concern in a particular language but not broadly, and so aren’t valid or aren’t answerable.
As noted by Ruth, there’s also the case where a question is posed multiple times. For example, in Portability, we find one question for each operating system. What is perhaps more appropriate is to frame the question to avoid the specificity and to avoid the potential impact on the score should a project only need to be delivered on one platform. (We currently don’t have an analysis of how this would affect scores through the TRL.)
While we’re going through this revision process, we’ll want to consider the criteria and any modifications in this light as well.

Okay, I said Agile.

Agile’s management. And it is often/sometimes used more as a design structure than an approach for developing good software. That’s awkward. It’s design in that it’s fairly feature-focused and iterative. The other is more that there’s nothing inherent in Agile itself that is about the kinds of criteria we’re discussing.
So we can bring it up, but you’ll need concrete and evaluatable criteria to support including it.
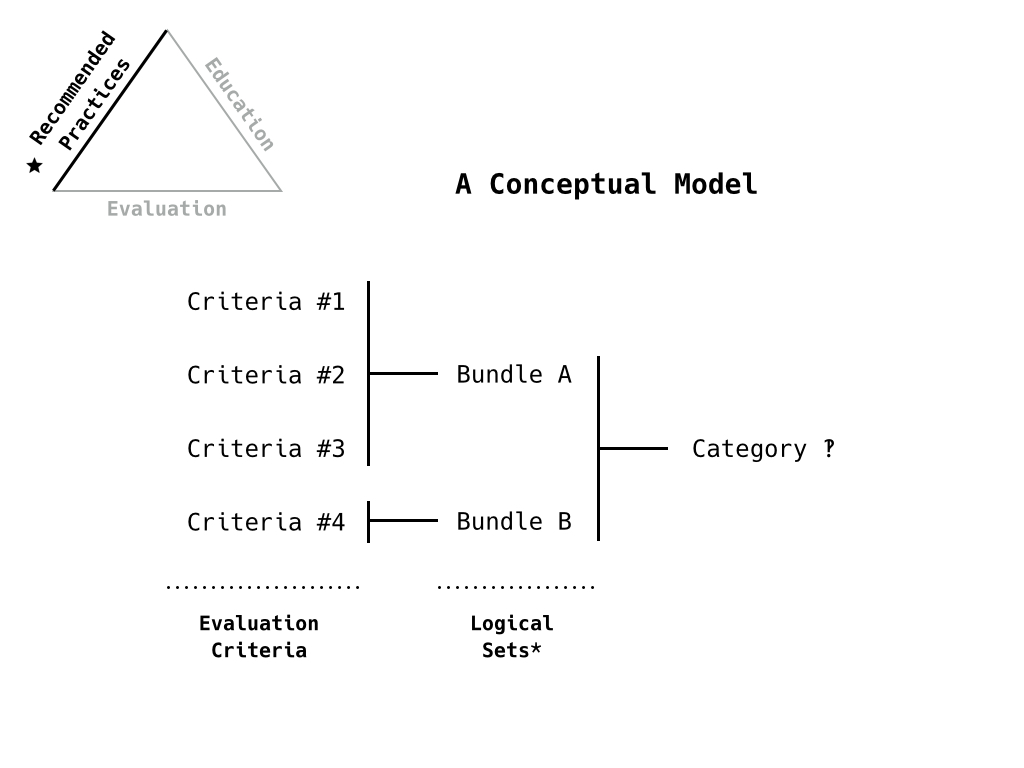
This is the kind of model we’re headed towards. The criteria, combined into some logical set (ie A doesn’t make sense without B), and captured in a category. This gives us ways to weight the different sections and gives us a way to support the education goals.
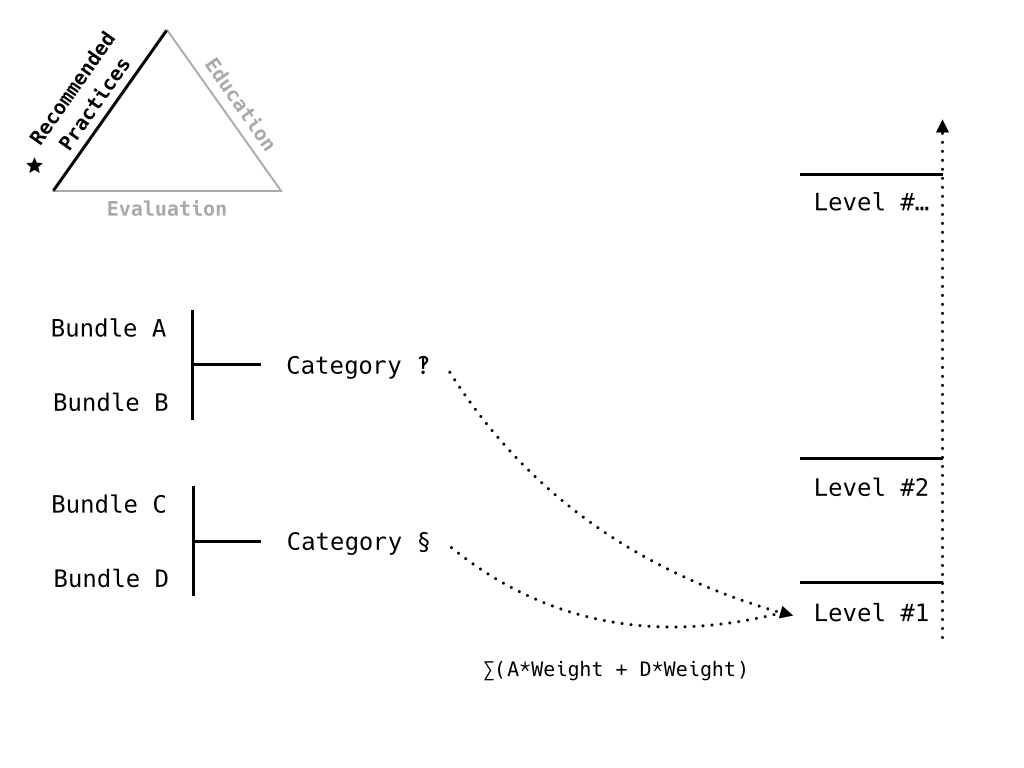
How the model relates to readiness levels/progression.
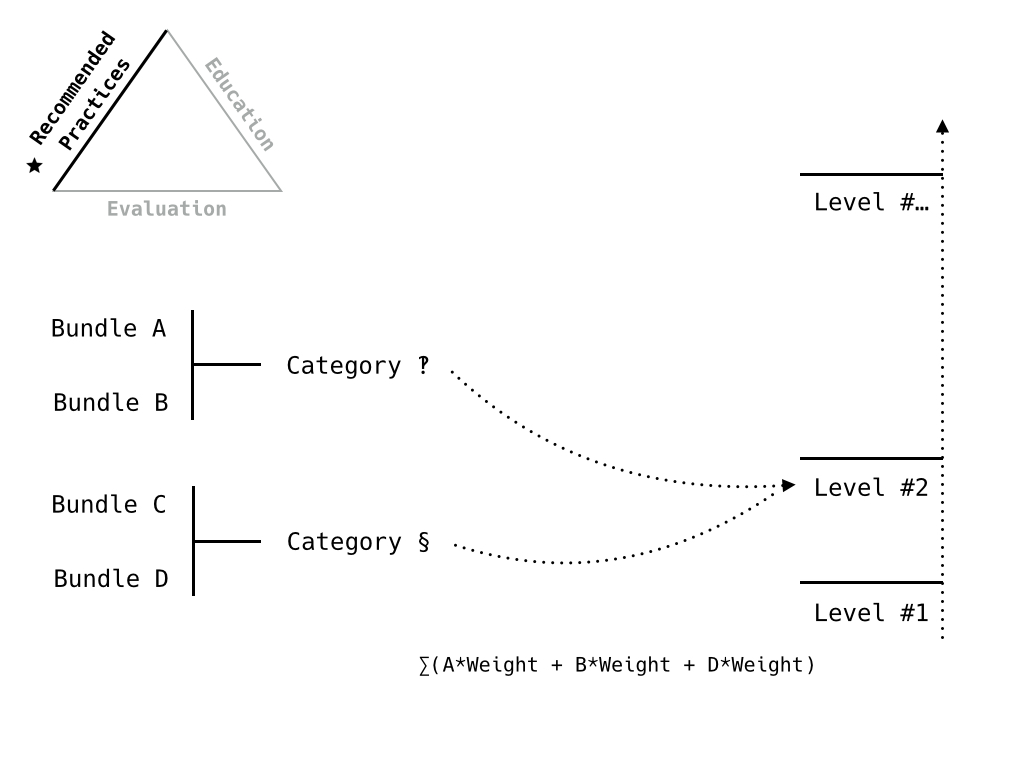
Next level, including additional criteria.
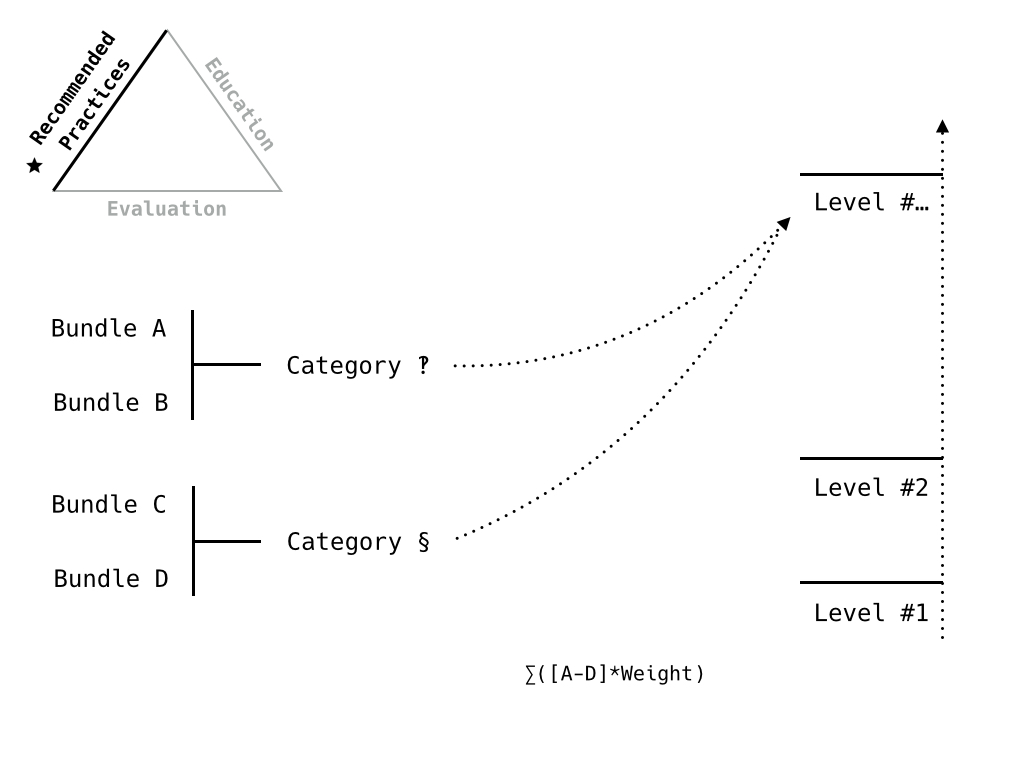
Final level, all the criteria.
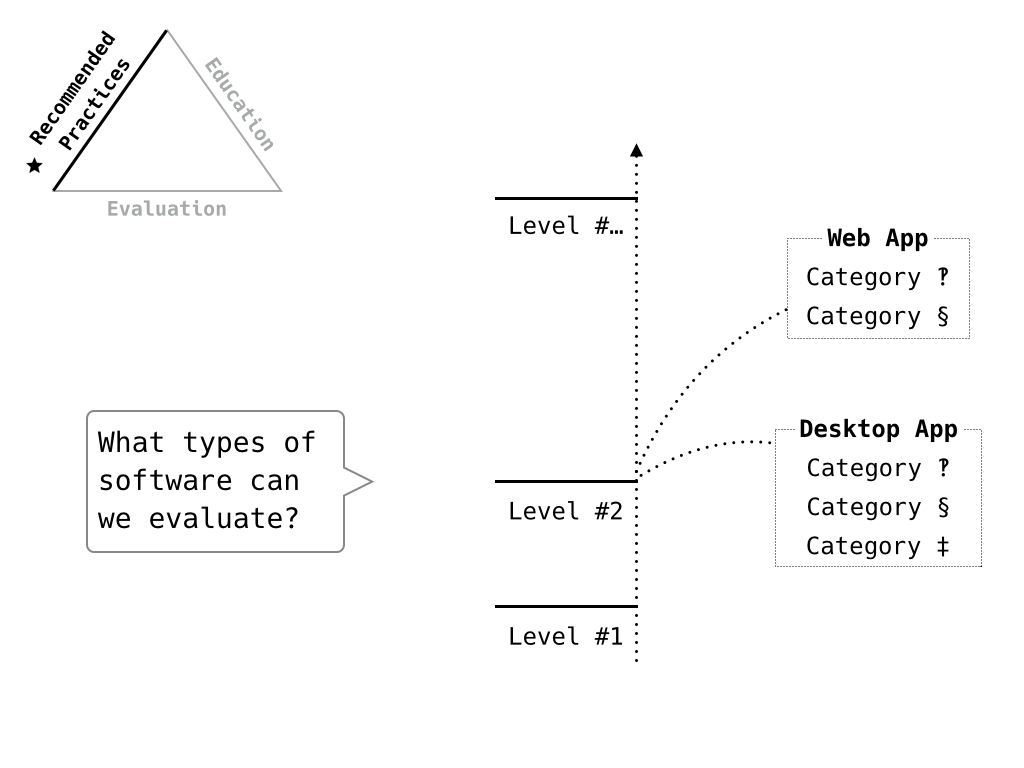
Now, we also need to consider the different kinds of software we need to evaluate, starting with common types found in research projects. So web applications, desktop apps, plugins/extensions, code modules.
Here again, a modular model let’s us customize the metric to these types of software so that we’re not asking evaluators to answer questions that don’t make sense for the type of project and that we’re not creating a metric so broad that it’s not effective for any software.

Of particular concern is the plugin/extension option. We want to assess the software written for the project, not the container, and the criteria need to reflect that.
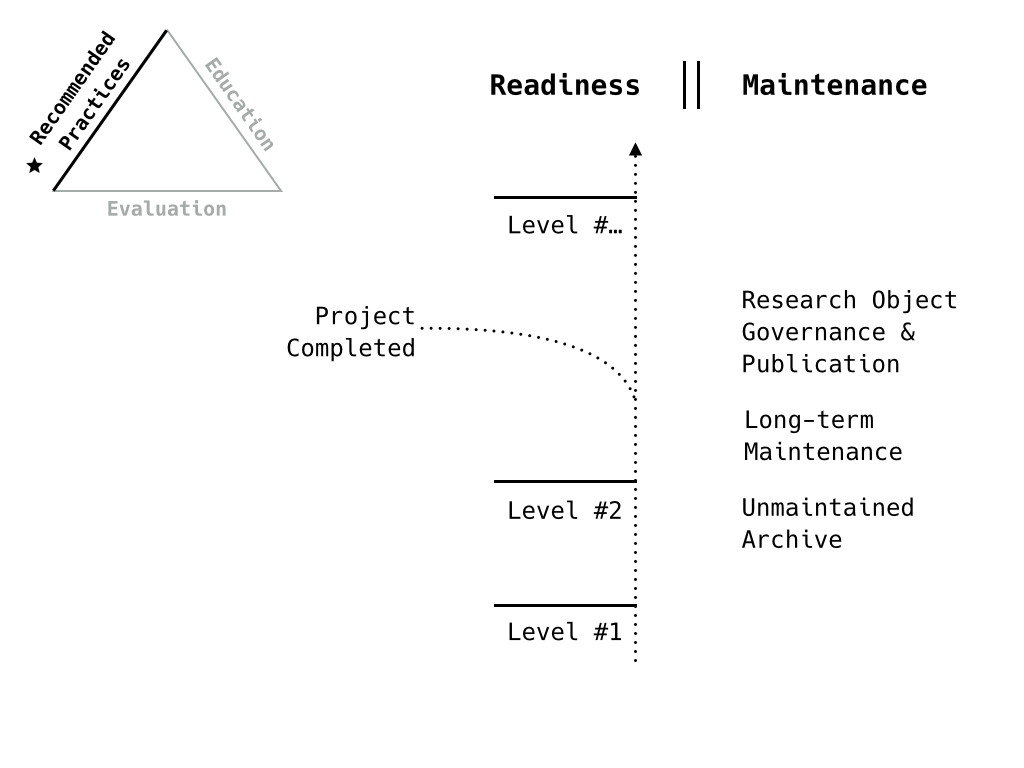
Maintenance has also come up in different conversations about readiness levels and evaluation. How do we evaluate the maintainability of the project at different levels?
What kinds of maintenance do we consider and what kinds of criteria would be involved for each?
It is readiness level-adjacent.

[See the NASA RRL references and criteria]
At some point, we’ll have to answer what reuse means - are we talking reproducibility or reuse? Or both?
How we plan on approaching this revision process, otherwise known as the software evaluation evaluation?
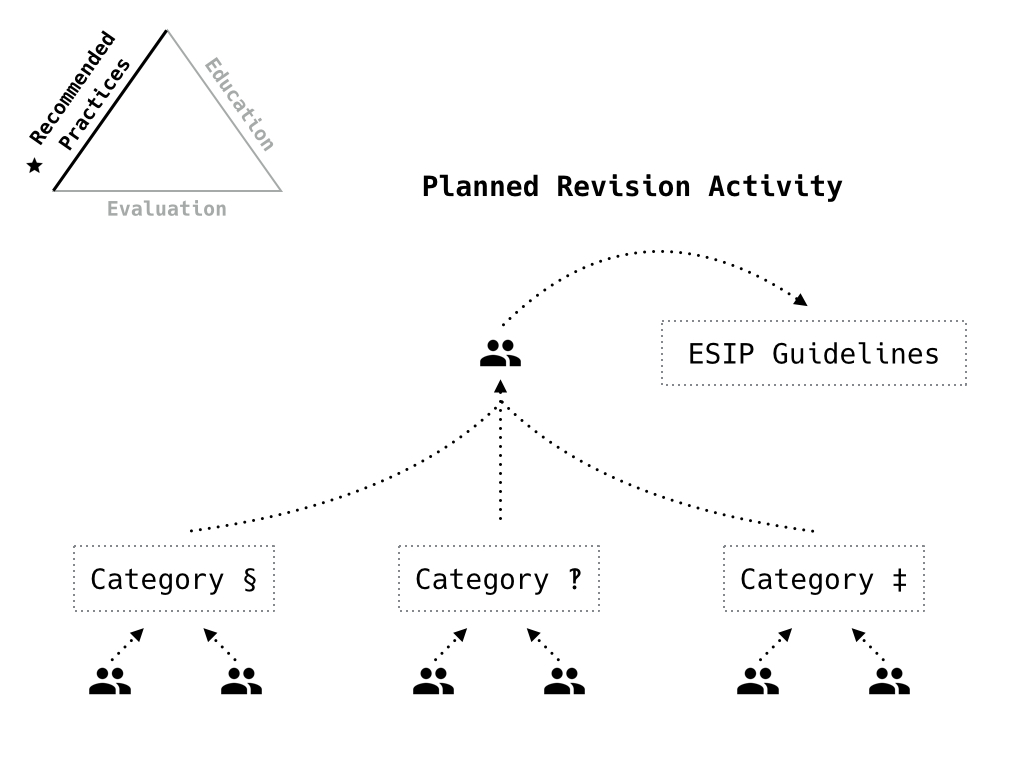
Sort of a cross between an annotation task and a Mozilla remote hackathon. Get small groups to go through each category and provide revisions and have a super group to synthesize the revisions into the final guidelines.
We want a decent number of eyes on the criteria and progression and we want to also provide everyone who wants to comment the opportunity to do so either just for the category of interest (the Data Stewardship crowd commenting on publication and archiving concerns, for example) or with limited time to offer (so contribute to one or two categories rather than the entire set).
We will, of course, credit all participants.

One of the first steps will be looking at the categories, identifying missing categories.

Next, in each of the categories, we’ll go through the criteria for abstraction issues, currentness issues (ie does it reflect the current state of software development with the example of “Supporting Internet Explorer” as something that is not so dreadful now), and other concerns.
We’ll want to also consider how to handle questions related to the project information and questions related to the software itself.

Finally, how do the revisions affect readiness levels and any kind of education scaffolding? Bear in mind that here we’re talking about an ESIP system and not a NASA system so the TRL is perhaps a guide but is not necessarily the goal.

Going back to our stakeholder list, we’d like to get a good mix of people involved, not just managers. Ideally, we’d like to get current developers involved so that we have a good balance. So if you can spare a bit of dev time and they’re game for a bit of meta-thinking, send them along.
The obligatory link to this site and also get in touch if you’re a BESSIG or ESIP member wanting to participate in any of these conversations. Door’s open.
Thank you.
Oh wow, that snow’s really coming down now.